Designing a Normalized Database
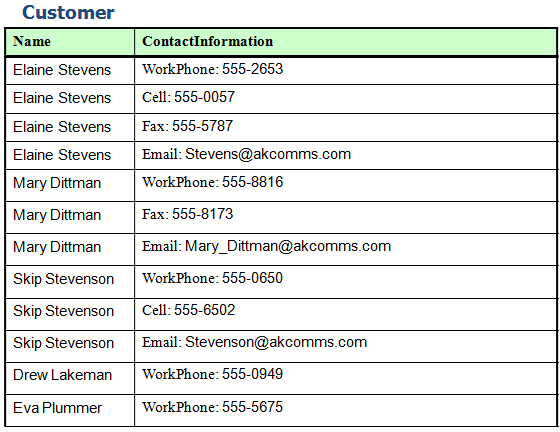
This is a flat table, sometimes called a flat file. All of the information is in a single grid, similar to a spreadsheet. We are going to reshape this information to make it smaller, faster, and easier to maintain.
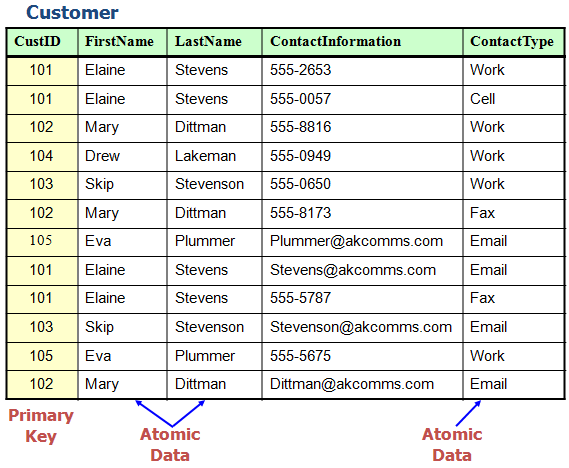
The first thing we do is split any columns which contain more than one type of information. In this next diagram the first and last names get their own columns, as do contact information and the type of contact information. This is called making the data "Atomic" in the sense of having been broken down as far as is possible. You an see that the contact information could be broken down further, but it is seldom worthwhile to separate the phone number into exchange and local number. Area code is sometimes stored in its own column.
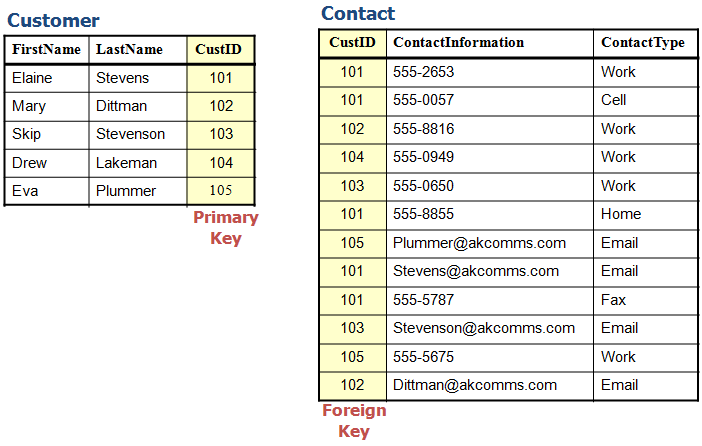
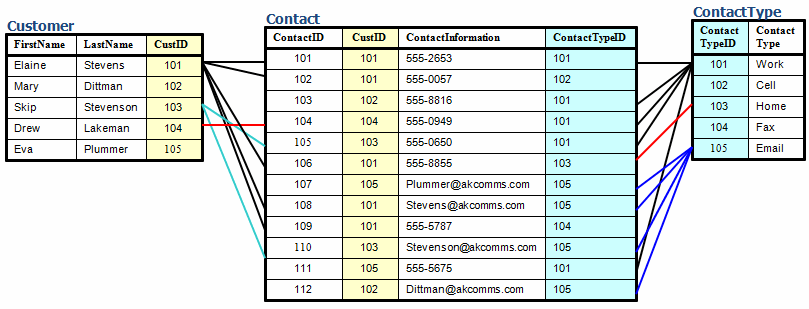
Next we want to reduce the amount of duplicate data. One way of doing that is to split the data into two tables. You can see that now each name is only recorded once, and each name (customer) has been assigned an ID. The data in the Customer table is now related to the data in the Contact table by CustID as shown in the next diagram.
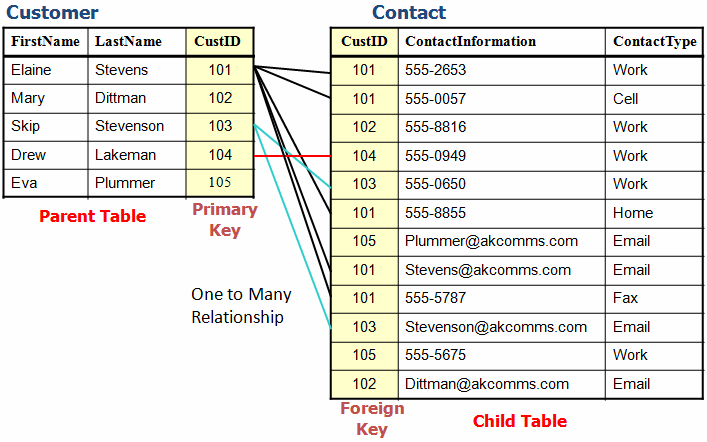
In the following diagram I have drawn lines to show some of the relationships created by matching CustID numbers. I have also added some labels for parent-child relations as well as Keys. The Primary Key must be unique. Each customer must have a customer ID, and no two customers can have the same ID. There is no real limit on Foreign Keys.
Finally we normalize ContactType by creating a ContactType table which has its own Primary Key. The Customer and ContactType tables have Primary Keys which match to Foreign Keys in the Contact table.
In a real database project CustomerID, Work Phone, Cell Phone, etc. would be written out. I have only abbreviated to make the diagrams fit on the Web page. |
My (Conrad Muller's) work on this page is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 2.5 License.